


We offer support to multiple databases where in each of the database is independent and the data are stored separately for ease of management and security reasons too.
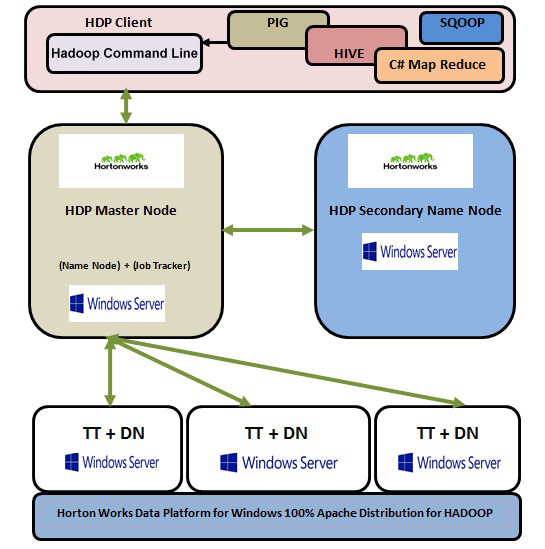
We have successfully done the Multi Node Cluster Configuration. In simple words, we have successfully created several Data Nodes to store huge volumes of data and separate HDP Master Node from Data Nodes. To manipulate the data we have also configured a HDP Client Node. A separate HDP Secondary Name Node will always be there to overcome the single point failure and to enhance the stability along with the reliability of the system.
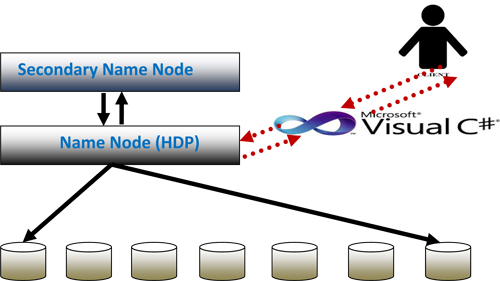
Storage of huge data cannot be the only purpose. Process and analysis of the extensive amount of data set to get the required results are the most important objectives. As the use of Hadoop is not the solution in Windows, hence we have implemented C# Map Reduce in Hortonworks data platform to process and analyze the extensive amount of data set in a very efficient manner.
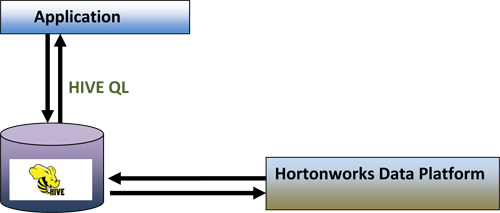
We have implemented HIVE Query Languages (QL) to process huge data set either from Hadoop or HIVE Data Ware House. This has enabled a large number of people to take the advantage of this technique as it has became much easier to write a query even with the knowhow of SQL.
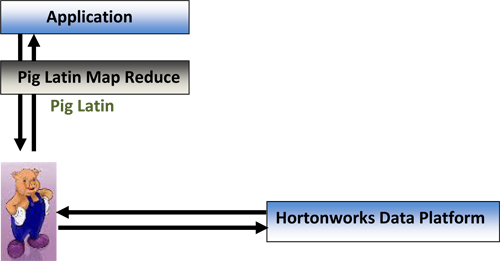
We have implemented PIG with PIG Latin to process large data set of Hadoop Cluster (HDP). In Hadoop, we store data in different Clusters of Commodity hardware and by use of processing language e.g. PIG Latin we can access them.
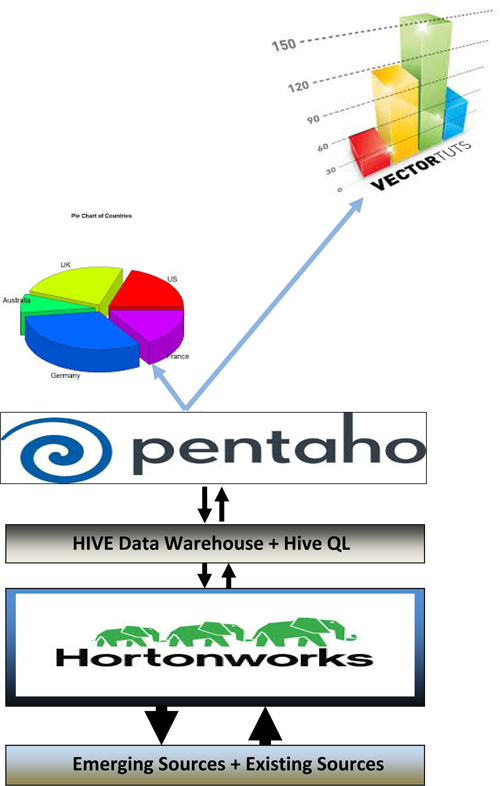
We have implemented Business Intelligence (BI) Tool like Pentaho to generate reports and charts for HIVE data warehouse. We can take data from HIVE data warehouse and using Pentaho we can generate reports through graphs or charts to represent data for analytical purpose.
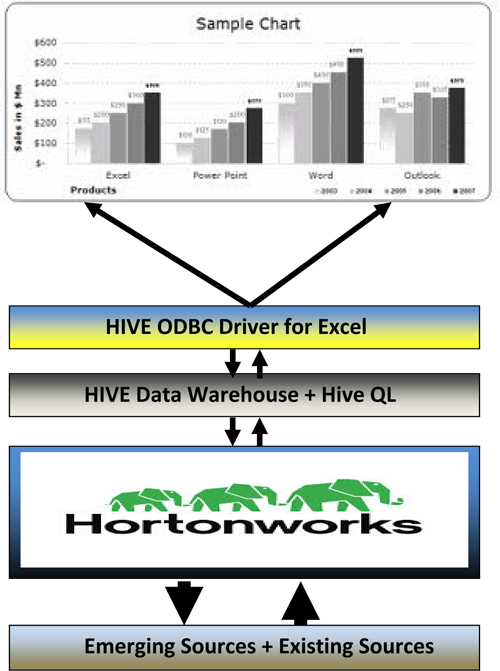
We have implemented famous Business Intelligence (BI) Tool Excel to visualize reports and charts for HIVE data warehouse. We can take data from HIVE data warehouse and using Excel HIVE ODBC Driver, we can generate reports through graphs or charts to represent data for analytical purpose.
Frequently encountered significant issues in Big Data and their solutions
- Often Name Node cannot be started after successful HDP 1.3 installation we have the solutions
- We can successfully separate Secondary Name Node from Name Node
- We have already found the reasons for not working of Replication factor setting in a proper manner and can also provide solution for that
- We have detected various reasons responsible for the issues faced to install the HDP on Windows Server 2008 R2 and we have the solutions to fix the same.
- We have diagnosed the specific reasons for the errors found to install HDP and also found the solutions to overcome those errors
- We can add a new slave node in to an existing cluster
- We can implement VS.Net HDFS Client Library.
- We have identified the reasons for Slave Node Host Name Quirk and Smoke Test failure and have already rectified the problem
- We have discovered the causes for non service of Single Node HDP for Windows and also possess the solutions
- We know why Hadoop service fails after successful installation and can make it a success.
- We have found the reason for the error in running Run-Smoke Tests command and can provide the solutions to make it error free.
- We can implement C# Map Reduce with HDP
Content Management and Delivery
Organizations building content-driven applications face new challenges - incorporating rich media, personalizing content in real-time, making content interactive, and supporting millions of users across multiple devices and platforms. To build next-generation content management and delivery applications, leading organizations are relying on MongoDB to realize accelerated time to market, new use cases and superior user experience.
Mobile and Social Infrastructure
Mobile apps and social networks are at once driving a technological sea change in the consumer and enterprise worlds and posing a new set of development and deployment challenges. MongoDB is empowering organizations of all sizes to capitalize on the opportunities in mobile and social by enabling new use cases, accelerating time to market and improving user experience.
Data Hub
Organizations generate enormous volumes of data and have a variety of tools to analyze, process, summarize and monetize information from different departments in many locations. Leading companies are turning to MongoDB to serve as the central data hub for all of their data because of its ease of use, scalability and low cost of ownership. MongoDB provides a universal repository in which data can easily be stored, processed and served to other applications.